
Knowledge retrieval transformers—WTF happened to WebGPT, GopherCite & RETRO?
Explore the Technology Behind New LLM tools like Writesonic, YouChat, Hello, Perplexity AI, MultiFlow, and ACT-1

About a year ago, OpenAI published their research on WebGPT, a model that can search and interact with a browser to answer your question. Deepmind followed suit with GopherCite, a 280 B parameter model that “backs up all its claims via citations with knowledge from the web”. Lastly, Deepmind released a paper on RETRO (Retrieval-Enhanced Transformer) a transformer connected to a 2-trillion text token database.
A massive win against the significant weakness of LLMs—their proneness to hallucinate, i.e., come up with plausible-sounding but wrong answers.
This kind of semi-autonomous research agent can retrieve factually correct/reliable data are, in many ways, more impressive than scaled-up LLMs chatbots (Maybe they also got less hype because there was no free demo?).
But what happened to this exciting technology, and why is Siri still stupid?
The broader area of these systems is called knowledge retrieval. This process seeks to return information in a structured form, consistent with human cognitive processes, as opposed to simple lists of data items (information retrieval). The specific sub-fiend in Machine Learning research is called Long-form question answering (LFQA). LFQA systems have the potential to become one of the main ways people learn about the world but currently lag behind human performance.
How does WebGPT work?
WebGPT is a system that uses a fine-tuned version of GPT-3 to answer questions accurately with the ability to search and interact with a browser. But how does this work? It's pretty simple. Your query starts the agent's web search. It can scroll around, click links and capture a bunch of text it determines informative. Finally, it synthesizes all the captured text into one coherent answer. How was this model trained?
Information retrieval model: This model's output is the browser commands to extract relevant paragraphs. It's trained on human demonstrations with Imitation Learning (Behavior cloning).
Text Synthesis Model: A GPT-3 model pre-trained for the synthesis task to combine all relevant paragraphs into one answer.
Reward model: Predicts the entire system's output trained on human feedback.
RLHF Fine-tuning: Improve Information retrieval model using the Reward Model

What is RETRO?
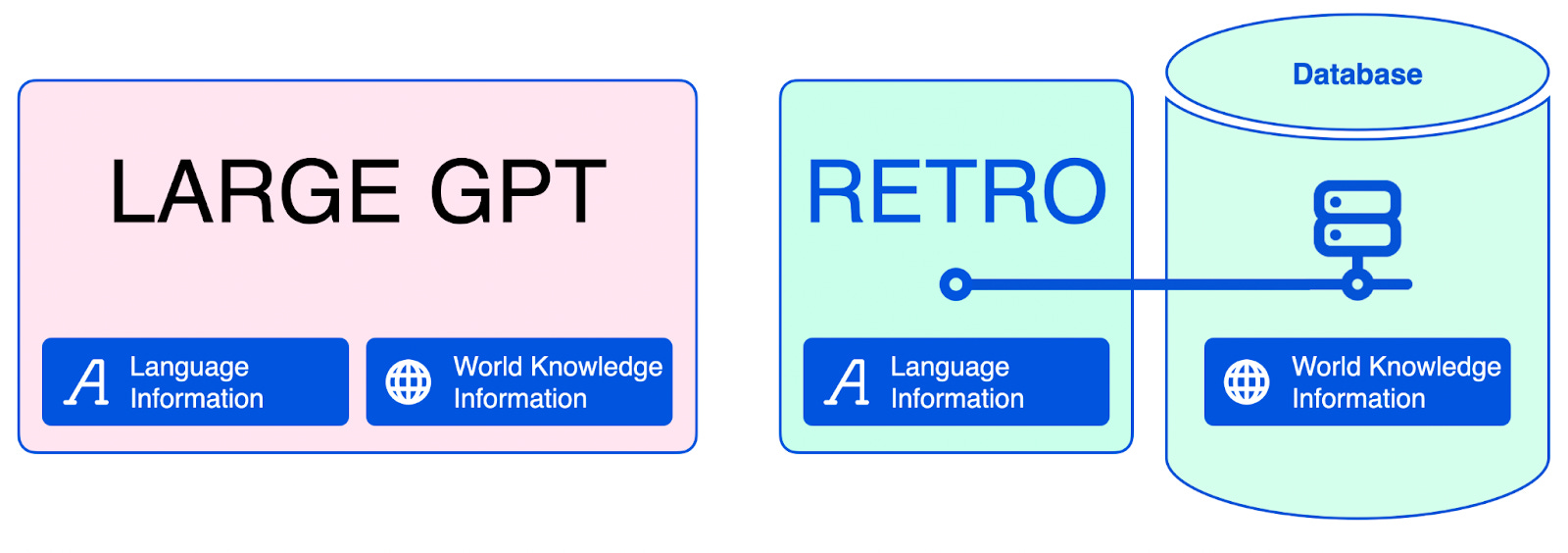
RETRO is a Retrieval Transformer. One problem with current large language models is their size, as they "memorize" large parts of the training data. To run GPT-3, one needs a 350 GB Ram (~22 GPUs) supercomputer.
Separating word knowledge into a database obtains comparable performance to GPT-3, with 25x fewer parameters.
Additionally, the technique is not only interesting for inference (as in WebGPT) but also for training. If the model could access information from an external knowledge base during exercise, it would not have to memorize everything in its weights but could simply look it up. Eventually, it could use its hundreds of billions of parameters for actual intelligence/learning capabilities instead of just remembering Barack Obama's birthdate.
Lastly, there is also the Differentiable Search Index (DSI) paradigm. This is a text-to-text model that can map string queries directly to relevant document IDs (docids) using its parameters alone.
The DSI paradigm differs from the RETRO approach in that it allows a model to answer queries using only its own internal representation of the data rather than relying on an external database or index like RETRO does by separating word knowledge into a separate database.
Products
Hello

UI/UX
Hello searches and understands technical sources for you, giving you actionable explanations and suggestions for your technical problems.
Hello shines when it comes to programming-related questions, as it can display code snippets as part of the generated answer.
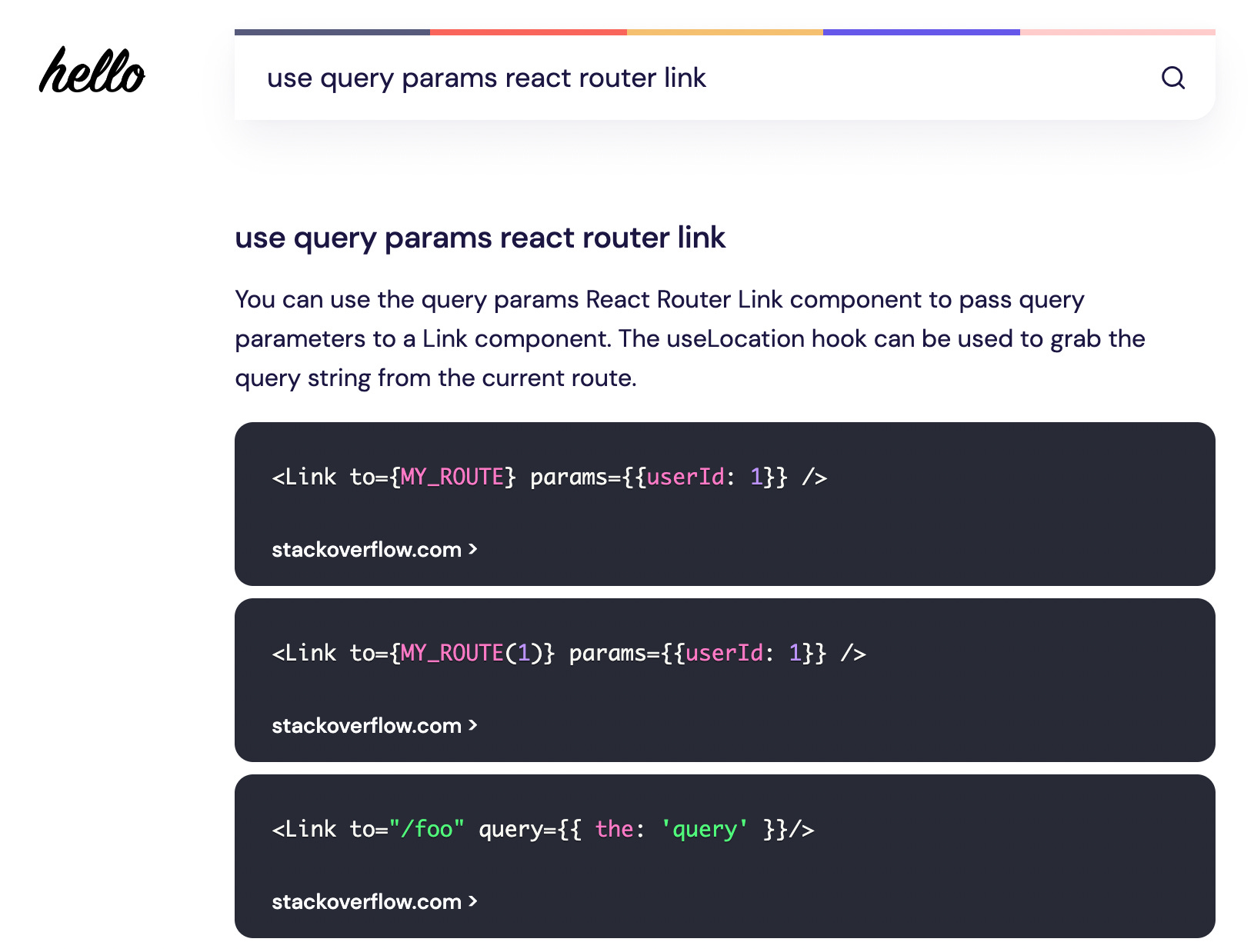
However, it’s good for non-technical questions as well. They also show a “Quick Answer” in addition to a “Detailed Answer” and “Background Answer” to answer all aspects of a user’s question (this might be called multi-depth-lvl-answer UX).
Model
Hello says it uses 1) a BERT-based model trained on a custom dataset to extract and rank text if relevant to the query and 2) an 11 B parameter model (T5-derivative) to synthesize the online sources into an answer. Hello is the only knowledge retrieval/generative AI search engine that uses its own models (Both YouChat and Perplexity use the GPT-3 API).
Perplexity AI

You can find less about Perplexity online but in their HN launch post they say that they are also "working on using LLMs to reword queries before searching and to make searches more conversational" which is pretty cool and likely critical for LLM-search companies to adapt their technology to existing Google user habits.
YouChat (You.com)
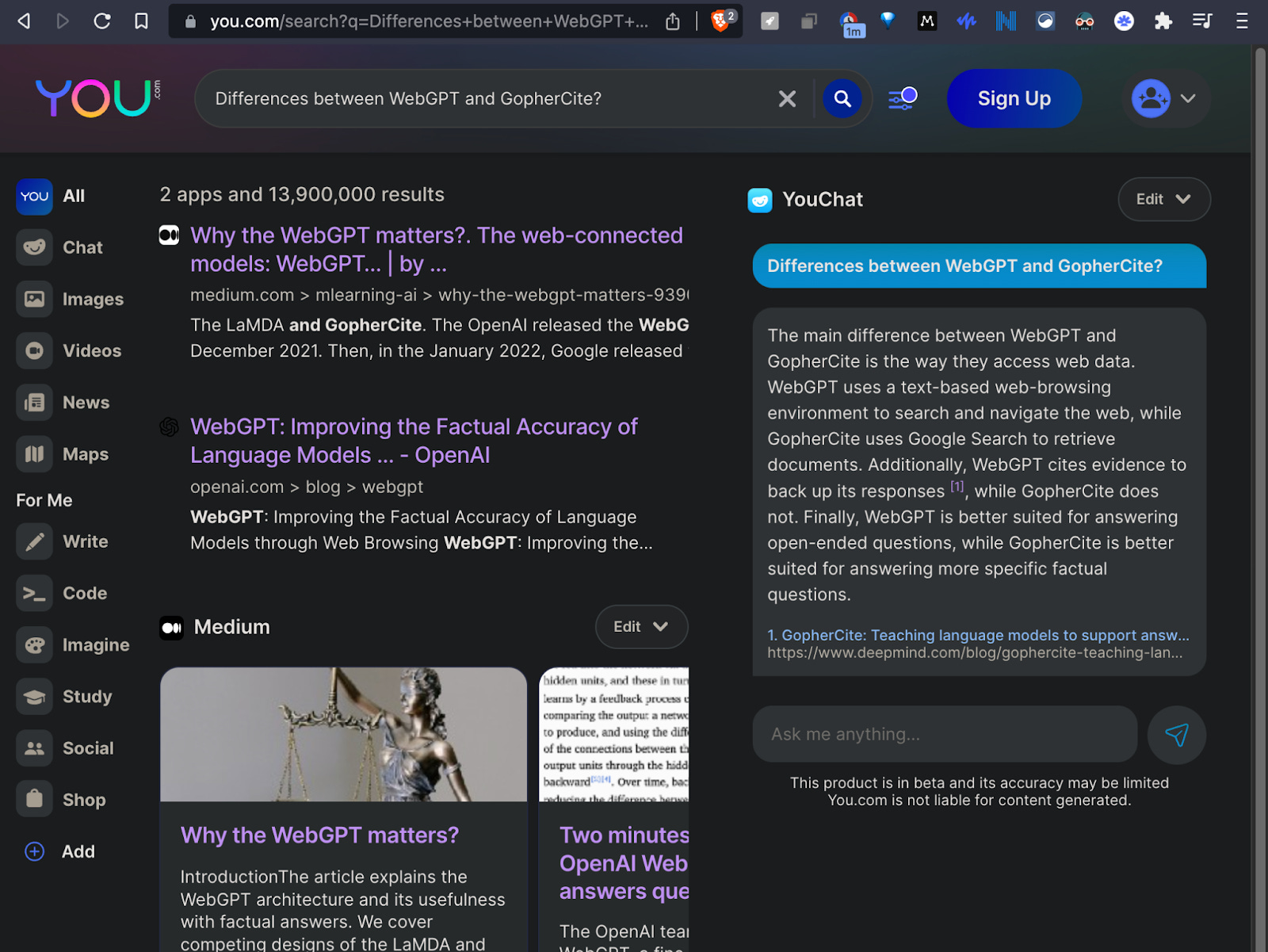
YouChat is the first product I saw that successfully integrated knowledge retrieval and chatbot responses. This duality is tricky because the model has to understand when to give a model-inference-based answer vs. when to extract the answer from the search query results, i.e., do knowledge retrieval. I don’t know how you get a model to make this decision (but please comment here if you know).
Chatsonic
Chatsonic - a chatGPT-like chatbot that integrates with Google Search to create content with the latest information. Additionally, it can create digital images and respond to voice commands.
Write sonic launched earlier today on Launch YC. It looks like it's the same product as YouChat. But it also has built-in image generation, voice input, and personalized avatars (you can chat with an English tutor, fitness trainer, math teacher, etc. I'd suspect this is just prompt engineering).
MultiFlow

I got the chance to beta test MultiFlow and am excited about the universality and possibilities of their platform. You can use it to help prototype products similar to the above-mentioned tools and deploy workflows incorporating various AI-driven abilities, such as chain-of-thought reasoning and grounded Q&A using a search engine. Multi has already used MultiFlow in-house to build a chatbot that can autonomously launch searches and extract/summarize the results to answer a question.
Action Transformer (ACT-1 by Adept)
ACT-1 is not just a knowledge retrieval agent but much more. It’s a large-scale transformer model trained to interact with software tools, APIs, and web applications i.e. piloting your browser. It can interact with any kind of web app via a Chrome extension (not just a search engine) and can correct mistakes after receiving human feedback. Adapt says that their goal with ACT-1 is to provide a natural language interface that allows users to tell their computers what they want directly, rather than doing it manually. A clear step towards prompting a new programming paradigm.
Why might this technology not be more popular yet?
Speed: As mentioned above, the speed and performance of these systems is not great. Many Google engineers spend years of their careers reducing the time between queries and presenting results by a few milliseconds. Google users are used to this lightning-fast experience which makes waiting a few seconds on your search query result an unpleasant experience.
Cost-per-search: Some rough napkin math—Bing is $0.007 per search, so if you are simply using results (as a knowledge retrieval), that’s almost $1 ct per search already. Assuming you’re summarizing ~400 words of these results, which is 1k tokens, that’s $0.0004-0.02 dollars depending on how good a model you use (It can be on the lower and if you train and deploy your own model). Google claimed in 2009 that they use 0.0003 kWh of electricity per amortized search, which at, e.g., 0.06 USD/kWh is $1.8*10^-5, or 0.26% of search cost. So, the cost per knowledge retrieval LLM search is magnitudes higher than a conventional search engine, which might make it harder to monetize it via ads.
Most web searches are document/site searches, not Q&A: When I use Google, it's mostly to navigate to some website, not to answer a profound question I have (most search queries are ~3 words long). This might be why search engines like Google or the LLM-powered metaphor.systems, which return a list of websites, are mostly preferred.
Most search one-shot: About 65% of searches are zero clicks. Meaning people get the answer from just the snippets on the results page.
Trust in Synthesized answers: I don’t have data on this, but I think many people don’t yet trust synthesized answers. They prefer to read straight from the source, even if the app provides citations.
It will be exciting to see the future of Knowledge retrieval products built on top of new transformer/LLM technology. Many variants seem unexplored. For ex., one could have an army of web research agents systematically dividing search territory to speed up the web research process.
Other fruitful areas of application of this tech are education and customer service. Students could get an interactive learning experience allowing them to access information and expert knowledge on demand. Customer service agents consulting a knowledge base could be augmented or replaced too.
The potential for agent-based knowledge retrieval systems to revolutionize how we access knowledge and interact with the web is undeniable.
Thanks to Matthew Siu, Johannes Hagemann, Michael Royzen, Harris Rothaermel and Emma Qian for comments!
Related papers/projects